AWS Bedrock + Claude Code 生产部署避坑实录:IAM 与 Guardrails 配置(2026)
目录
去年我们团队有个做法被我坚决否了——直接用 Anthropic 官方 API Key 跑生产流量。
答案先行:Bedrock 不是 AWS 版的 API 中转站。它给你的核心价值是 VPC 内网隔离 + IAM 细粒度权限 + CloudTrail 全量审计 + Guardrails 原生集成。这四件事放在一起,才是你从 Anthropic 官方 API Key 迁到 Bedrock 的充分理由——尤其当你的团队超过 5 个人或处理用户数据的时候。
原因很简单:一个 API Key,裸奔在生产环境里,没有 IAM 权限隔离,没有 VPC 内网流量,请求日志也不在我们自己的账号里。更要命的是,国内访问 Anthropic 的 API 端点本来就不稳定,偶发的连接超时在批量任务里会变成灾难性的连锁失败。
折腾了两周之后,我们把整套架构迁到了 AWS Bedrock。这篇文章想把这三个月里真正踩过的坑、做对的决策、以及那些文档里没写清楚的细节都说一遍。不是入门教程,是工程视角的实战记录。
为什么 Bedrock + Claude Code 的组合值得认真对待
很多人对 Bedrock 的印象还停在”AWS 版的 API 中转”这个层面,觉得不就是换了个调用端点吗。这个认知是错的,而且错得比较彻底。
Bedrock 给你的不只是一个调用 Claude 的地址,它给你的是整个 AWS 的安全和可观测性基础设施。具体体现在四件事:
流量完全走 VPC 内网。 你的应用实例到 Bedrock 的 API 调用,可以配置走 VPC Endpoint(PrivateLink),请求不出 AWS 骨干网,不产生出站流量费,也不暴露在公网上。这对处理敏感数据的企业来说是硬需求。
IAM 精细化权限控制。 你可以控制哪些角色能调用哪些模型,哪些模型能用 Claude Sonnet 4.6,哪些只能用 Haiku。这种细粒度的权限管理在官方 API Key 模式下根本不存在。
调用记录落进 CloudTrail。 每一次 InvokeModel 请求,是谁调的、调了什么模型、什么时间、请求了多少 token,全部有日志可查,满足企业合规审计的要求。
Bedrock Guardrails 原生集成。 你不需要在应用层自己写内容过滤逻辑,Guardrails 直接挂在 Bedrock 调用层,输入输出的 PII 脱敏和有害内容过滤在 SDK 层面就处理掉了。如果你之前已经在用 Guardrails 配了安全策略,可以参考 Bedrock Guardrails 三线模型 中的配置思路。
这四件事加在一起,才是 Bedrock 和”找个中转站”的本质区别。如果你的业务涉及用户数据、有合规审计要求、或者团队超过五个人,选 Bedrock 不是可选项,是理所当然的选择。
环境搭建:跳过向导,直接说正确姿势
AWS 官方文档里有一个登录向导(/setup-bedrock),对于初次使用者来说挺好用,但在企业多账号、CI/CD 环境、或者需要统一管理的场景下,向导的交互方式是行不通的。
Step 1:申请模型访问权限
很多人在这一步没搞清楚一件事:Bedrock 上的 Claude 模型需要先手动申请访问权限,而且每个 AWS 账号做一次,不会自动开通。如果你的账号是通过代理商开的,还要确认代理商有没有 Anthropic 合作资质,否则模型申请可能直接被拒。
登录 Bedrock 控制台 → Model catalog → 找到 Anthropic 的 Claude 系列 → 提交 Use Case 表单。表单很简单,填一下使用场景,提交后通常是立即批准的。
如果你用的是 AWS Organizations 管理账号,可以用 PutUseCaseForModelAccess API 在管理账号统一提交,子账号自动继承权限,不需要每个子账号单独去点。
Step 2:IAM 权限配置
最容易配错的地方。最小权限原则:给执行 Claude Code 任务的角色只授予必要的 Bedrock 权限,而不是把 bedrock:* 全部放开。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-sonnet-4-5-20251001-v1:0",
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-haiku-4-5-20251001-v1:0"
]
}
]
}把 Resource 限定到具体模型 ARN,而不是 *。这样即使某个服务角色被误用,也只能调指定的模型,调不了其他 Bedrock 资源。
Step 3:Claude Code 环境变量配置
对于开发者本地环境:
export ANTHROPIC_PROVIDER=bedrock
export AWS_REGION=us-east-1
export ANTHROPIC_MODEL=us.anthropic.claude-sonnet-4-5-20251001-v1:0
export CLAUDE_CODE_USE_BEDROCK=1注意 ANTHROPIC_MODEL 里的模型 ID 格式。跨区域推理(Cross-Region Inference)的模型 ID 前缀是 us. 或 eu.,和 Bedrock 直调的模型 ID 有区别。这个差异曾经让我们的一个服务连续报 ValidationException 报了两个小时。
- 跨区域推理格式:
us.anthropic.claude-sonnet-4-5-20251001-v1:0 - 直接区域调用格式:
anthropic.claude-sonnet-4-5-20251001-v1:0
生产环境我强烈建议用跨区域推理,吞吐量更高,某个 Region 出问题时自动路由到其他 Region,稳定性好一个档次。
Claude Code 在 Bedrock 上的实际工作方式
很多人对 Claude Code 的理解还停在”一个对话 AI 工具”这个层面。但在企业工程实践里,Claude Code 的核心价值是它作为一个 Agentic AI 编程助手,能够自主规划、执行多步骤任务的能力。
接进 Bedrock 之后,这个能力和企业的基础设施形成了真正的结合。
代码审查自动化
我们现在的 PR 流程里,Claude Code 通过 Bedrock 跑在 GitHub Actions 里,每个 PR 自动做代码质量分析:
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_ROLE_TO_ASSUME }}
aws-region: us-east-1
- name: Claude Code Review
uses: anthropics/claude-code-action@v1
with:
use_bedrock: "true"
claude_args: |
--model us.anthropic.claude-sonnet-4-5-20251001-v1:0
prompt: |
审查这个 PR 的代码变更,重点检查:
1. 潜在的安全漏洞(SQL 注入、XSS、不安全的反序列化)
2. 边界条件处理是否完整
3. 错误处理是否规范
4. 是否引入了明显的性能问题
输出结构化的审查意见,区分 blocking 和 non-blocking 问题。一个踩坑点:OIDC 认证方式比 Access Key 安全得多,但 role-to-assume 对应的 IAM Role 需要在信任策略里允许 GitHub Actions 的 OIDC 提供商。很多人配完发现权限报错,往往是信任策略里的 Condition 写错了 repository 名称。
RAG 知识库问答
我们有一套内部文档问答系统,用的是 Bedrock Knowledge Bases + Claude。S3 存放文档,Bedrock 负责向量化索引和检索,Claude 负责生成答案。整个系统完全在 VPC 内部流转,文档内容从来不出 AWS 边界。
这套架构解决了一个困扰我们很久的问题:以前用外部的 RAG 服务,工程文档和内部设计文档传出去总是不放心。现在数据主权完全在自己手里。
批量代码生成任务
我们有一个内部工具,从 API 规范文档自动生成对应的测试用例骨架。每次服务接口更新,跑一次生成任务,省去手动写 test boilerplate 的时间。
这类批量任务用 Bedrock 的另一个好处是吞吐量。官方 API 在高并发请求时容易触发 rate limit,而 Bedrock 的并发限制更高,通过跨区域推理池可以进一步提升吞吐。
Guardrails:不配比配错更危险
这是我见过最多人踩坑的地方。很多团队知道 Guardrails 这个功能,也确实配了,但配出来的效果要么是拦截太激进导致正常业务被误判,要么是形同虚设根本没保护到关键路径。
根本原因在于:在配置 Guardrails 之前,没有先想清楚三件事。
数据红线:哪些字段绝对不能出现在模型输入或输出里
我们的系统处理用户的个人信息,在配置 PII 过滤之前,我先列了一张表:哪些是必须过滤的(手机号、身份证号、银行卡号),哪些是”最好过滤但不是 blocking 的”(姓名),哪些是完全不用过滤的(行业术语、产品名称)。
这张表决定了 Guardrails 里 PII entity 的配置范围。如果不先列这张表直接上手配,往往会走两个极端:要么把所有 PII 类型都打开,导致正常业务内容被误判;要么图省事只配了最常见的,把不常见但危险的字段漏掉了。
行为红线:模型被允许做什么、不被允许做什么
这和内容过滤不同。内容过滤是关于”说什么”,行为红线是关于”做什么”。比如,我们的内部问答助手不应该给用户提供法律建议;代码审查助手不应该主动帮用户修改代码文件,只能输出审查意见。
这类限制应该同时在两个地方设置:Guardrails 的 Topic denial 配置,以及系统 prompt 里的明确指令。单靠 Guardrails 不够,单靠 prompt 也不够,两者一起才是防线。
话题红线:不能触碰的内容领域
Guardrails 的 topic 匹配是基于语义相似度而不是关键词匹配,所以不需要列举所有可能的关键词,只需要描述清楚这个话题的语义范围。
实际配置的 Topic Denial 描述应该写得具体,比如:“任何关于竞争对手产品价格、功能对比的讨论”,而不是”竞争对手”这种模糊的关键词。描述越具体,误判率越低。

成本控制:token 消耗是看不见的出血口
接进 Bedrock 之后,计费方式从 Anthropic 官方 API 的”每月充值然后用光”变成了 AWS 账单的按 token 计费。有几个细节会让账单出乎意料地高。
系统 prompt 的 token 成本
很多开发者写系统 prompt 喜欢写得很详细,三四百个 token 的系统 prompt 很常见。但每次 API 调用,系统 prompt 的 token 全部算输入 token 计费。如果你的系统一天调用一万次,一个 400 token 的系统 prompt 就是 400 万输入 token 的纯额外成本。
优化方向:把系统 prompt 里能用简洁语言表达的内容压缩,去掉例子和说明,只保留约束和指令的核心。通常一个 400 token 的系统 prompt 可以压缩到 150-200 token 而不损失效果。
上下文窗口管理
多轮对话的历史消息也是输入 token。如果对话历史不加管理,随着对话长度增加,每次调用的成本是线性增长的。
对于内部问答场景,我们做了一个简单的上下文修剪策略:保留最近 5 轮对话,同时在系统 prompt 里加一句”如果问题是独立的请直接回答,不需要参考之前的对话”。对于大多数业务场景,这样已经够用,成本比保留全量历史低 60% 以上。
模型分级调用
不是所有任务都需要 Claude Sonnet,更不是所有任务都需要 Claude Opus。我们的分级策略:
| 场景 | 模型 | 策略 |
|---|---|---|
| 代码审查、复杂推理 | Claude Sonnet 4.6 | 高质量,按需使用 |
| 简单问答、内容分类、摘要 | Claude Haiku | 低成本,高频调用 |
| 批量文本处理 | Batch API | 比实时推理低 50%,延迟不敏感场景首选 |
Bedrock Batch Inference 是一个很多人没用起来的功能:你提交一批输入,Bedrock 异步处理,完成后把结果写到 S3。对于离线数据处理、报表生成、大批量文档分析,用 Batch Inference 比实时调用省一半的钱。和 AWS 成本优化指南 中提到的一样,大部分人高估了”选对机型”的省钱效果,却低估了”选对调用方式”带来的成本差异。
跨 Region 可用性:不要把鸡蛋放在一个区域里
2026 年以来有过几次 Bedrock 单 Region 的服务降级,只调 us-east-1 的团队都中过招。跨区域推理(Cross-Region Inference)是解法,但要配对了才有用。
import boto3
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
response = bedrock.invoke_model(
modelId='us.anthropic.claude-sonnet-4-5-20251001-v1:0', # us. 前缀触发跨区域推理
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [{"role": "user", "content": prompt}]
}),
contentType='application/json',
accept='application/json'
)us. 前缀会让 Bedrock 在 us-east-1、us-west-2、us-east-2 之间自动路由,任何一个 Region 可用性下降时流量自动切到其他 Region。
对于欧洲用户,对应的前缀是 eu.,涵盖 eu-west-1、eu-central-1 等欧洲区域。亚太区域目前跨区域推理覆盖有限,这是 Bedrock 在亚太用户中体验不如美区的主要原因之一。如果主要面向亚太用户且对可用性要求很高,可以考虑多区域主备架构,在应用层实现 failover 逻辑。
完整生产架构图
把上面说的东西串起来,我们现在的架构大致是这样:
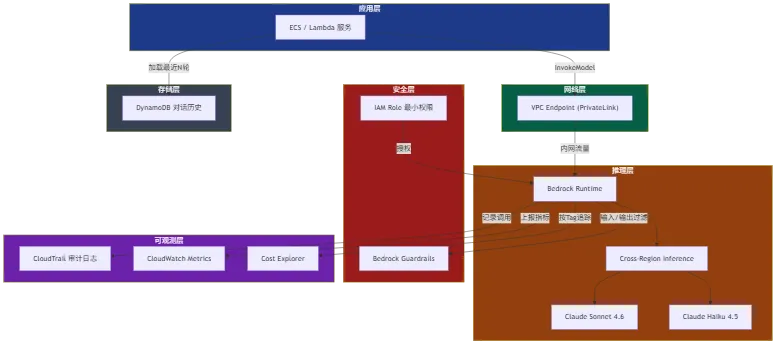
- 应用层(ECS/Lambda)→ VPC Endpoint(PrivateLink)→ Bedrock Runtime → Claude 模型(跨区域推理)
- 权限层:应用层的服务角色通过 IAM Role Assumption 获取 Bedrock 调用权限,最小权限,只开放必要的模型 ARN
- 安全层:Bedrock Guardrails 挂在调用路径上,系统 prompt 级别的行为约束 + Guardrails 的内容过滤双重保护
- 可观测层:CloudTrail 记录所有 InvokeModel 调用,CloudWatch Metrics 监控 token 消耗和延迟,Cost Explorer 按 tag 追踪不同业务线的 AI 成本
- 存储层:对于需要长上下文的场景,历史对话记录存在 DynamoDB,每次调用时按需加载最近 N 轮,不维护全量历史
这套架构跑了三个月,没有出现过安全事件,成本在可控范围内,服务可用性比之前用官方 API 好了不止一个量级。
那些文档里没写清楚的细节
按踩坑顺序记录,省得你们重复踩:
- Unsupported Countries 报错不是你的网络问题。先去 Bedrock 控制台确认模型访问权限状态,再查网络。如果是通道合作伙伴账号,确认代理商有 Anthropic 资质。
/setup-bedrock向导在 EC2 实例上会卡住,因为实例上没有浏览器。在无头环境里直接用环境变量配置,不要依赖向导。- Guardrails 误判会触发
AccessDeniedException而不是内容过滤的专用错误码,初期我们以为是权限问题排查了很久。遇到AccessDeniedException先去 CloudTrail 看调用记录,确认是权限还是 Guardrails 触发。 - 模型 ARN 的 Region 和你实际调用的 Region 必须匹配。用跨区域推理的话,模型 ARN 里写
us.前缀,不要写具体 Region 的 ARN。 - Batch Inference 输入格式是 JSONL,不是 JSON,每行一个请求对象,整个文件放到 S3,然后用
CreateModelInvocationJob提交任务。
用了三个月,最大的体会是:Bedrock 不是一个让 Claude Code 变得更复杂的中间层,而是让企业能在真正放心的前提下用起 Claude Code。数据不出境、权限可审计、成本可追踪,这三件事做到了,AI 编程工具才能进生产环境。
关于 SevenColorYun
作为 AWS 高级合作伙伴(Advanced Tier),同时持有 Anthropic 直接合作协议,SevenColorYun 已为 80+ 企业提供 AWS 代理采购与 AI API 代付服务。
我们的服务:
- AWS Bedrock 生产环境接入咨询(IAM 权限配置、Guardrails 安全策略、跨区域高可用架构)
- Anthropic API 直连代付(Claude Opus/Sonnet/Haiku 全系列,支付宝/微信/USDT)
- AWS Bedrock 通道商账号迁移(同时持有 AWS Partner + Anthropic 合作的代理商)
- 灵活付款:USDT/对公转账(香港支持 FPS 转数快、新加坡支持 PayNow),支付宝/微信亦可,支持月结,可开海外 Invoice 或国内发票
正在做 Bedrock + Claude Code 生产部署?点击右下角联系技术顾问,获取 AWS 代理商服务 专属架构评估与接入方案。
相关阅读
- AWS Bedrock Claude 模型申请被拒怎么办?三种绕过方案的完整代价对比与实测
- Bedrock Guardrails 配错比不配更危险:AI 安全三线模型与三个真实踩坑案例
- AWS Kiro vs Cursor:三个团队 90 天真实生产报告
- 云服务器代理商怎么选不踩坑?6 维度筛选指南
- AWS 成本优化指南:代理商充值赠金拿到了,为什么账单还在涨?
- 中国开发者接入海外大模型 API 完整指南:Claude/GPT/Gemini 三模型五路径决策框架 — Bedrock Claude Code 生产部署只是 AI API 全景的 AWS 路径,这篇把三模型五条路径的全貌展开


