Kiro Steering Files 实战模板:3套可复制的团队规范配置
目录
前言
Steering Files 不是团队文档——是写给 AI 看的代码约束。它跟 README 和 Wiki 的区别就一个:人看不懂还能猜,AI 猜不了,它会照做。
2026 年 2 月到 4 月,我帮 12 个开发团队配了 Steering Files(Kiro 官方对 Steering Files 的设计理念见 kiro.dev/docs/steering)。前 3 个团队全失败了:文件写完两周没人看,一个月后 AI 生成的代码回到老样子。后面 9 个团队成了,PR 里规范相关的评论从 30% 左右降到 6% 以下。
差距在哪?前 3 个团队把 Steering Files 当文档写给人看。后 9 个团队写给 AI 看。
本文提供 3 套可直接复制的模板(代码风格/安全/性能),每条规则附设计理由,让你不用从零摸索。最后给一套轻量治理流程,防止文件写完就腐烂。
一、为什么 Steering Files “写完就没人维护”?三个团队的失败模式
Answer Capsule: Steering Files 失败的第一因不是团队懒,是写错了受众。给人看的规范文档用”建议使用统一的错误处理模式”,AI 看不懂”统一”指什么。给 AI 看的约束文件用”所有 async 函数返回 Result<T, Error>,禁止 throw”。前者是愿望,后者是指令。
让我用三个真实失败案例说明这个区别。
案例 A(2026 年 1 月,深圳 5 人 SaaS 团队): 他们在 .kiro/steering/naming.md 里写了”变量命名应保持语义清晰”。这不是约束,是愿望。Kiro 生成的代码中,同一个用户 ID 字段在三个文件里变成了 userId、user_id、userIdentifier。文件写了等于没写。
案例 B(2026 年 2 月,上海 3 人金融科技团队): 他们把公司内部 Wiki 的编码规范(38 页)原样复制到 Steering Files 里,拆成 6 个文件。结果 Kiro 的上下文窗口被规范占满,生成业务代码时反而丢失了需求细节。6 个文件两周后全被删了。
案例 C(2026 年 3 月,成都 8 人远程团队): Steering Files 写得没问题,但没指定谁负责维护。两个月后,项目从 React 18 升级到 React 19,规范里还写着”使用 React 18 的 Suspense 模式”。新人用 Kiro 生成的代码跟现有架构脱节,文件成了负资产。
三个案例的根因指向同一个结论:Steering Files 不是”写一次就完事”的文档资产,是”需要持续修剪”的代码约束。 写法和管理方式都要变。

Brian 的建议:开工前先回答三个问题。谁负责每周维护这组文件?(指定一个人,不是”团队共同”)每个文件的目标读者是 AI 还是人?(如果是人,放到 Wiki 去)这个文件 3 个月后还有效吗?(如果没有明确答案,说明里面的规则太虚了)
二、模板一:coding-standards.md 怎么统一代码风格?
Answer Capsule: 代码风格文件的核心原则:每句话必须是 AI 可以直接执行的指令,不含”建议""应该""尽量”等模糊词。14 行覆盖命名/文件结构/错误处理三个维度,每条规则都是 yes/no 判断,AI 没有”理解偏差”的空间。
复制以下内容到 .kiro/steering/coding-standards.md:
# Coding Standards
## Naming
- Variables and functions: camelCase (`getUserById`, `isLoading`)
- React components: PascalCase (`UserProfile`, `PaymentForm`)
- Constants: UPPER_SNAKE_CASE (`MAX_RETRY_COUNT`, `API_BASE_URL`)
- Database columns: snake_case (`created_at`, `updated_by`)
- Avoid abbreviations in public APIs (use `configuration`, not `cfg`)
## File Structure
- One exported component per file
- Every module exports from a single `index.ts` barrel file
- Test files co-located with source: `Button.test.tsx` next to `Button.tsx`
## Error Handling
- All async functions return `Result<T, AppError>` type
- Never use `throw` for control flow
- Every API route handler wraps body in a try-catch that returns structured error JSON每条规则的设计理由:
命名规则选 camelCase/PascalCase/snake_case 三套并存,因为全栈项目天然跨 JS/React/数据库三层。不统一到一套命名体系(比如全用 camelCase),理由很简单:ORM 的蛇形命名转换不是每个团队都开了,直接在规范层做好映射更安全。
禁止缩写这条容易被忽略,但它对 AI 生成代码特别重要。人类开发者知道 cfg 在某个上下文里是 configuration,AI 不知道。AI 看到 cfg 会在不同文件里分别理解成 config、configure、configuration,然后生成不一致的变量名。
错误处理统一 Result<T, AppError> 模式,这条是最容易引发跨模块不一致的地方。2026 年 1 月一个 7 人团队在这个问题上踩过坑:同一套 API,两个开发者让 AI 生成了两种错误处理模式(Result 模式 vs Exception 模式),合并后调用方要适配两套逻辑,修了两天。
Brian 的建议:命名和文件结构规则不需要频繁改,一次配置管 6 个月没问题。但错误处理模式要在团队内达成共识再写进去:这条规则每天都会被触发几十次,写错了代价很大。
三、模板二:security-guardrails.md 怎么防止 AI 写出安全漏洞?
Answer Capsule: 安全规范是所有 Steering Files 里唯一”即使单人开发也必须配置”的文件。AI 生成代码的安全漏洞不随团队规模变化。20 行覆盖输入校验/SQL 注入防护/租户隔离三个高频风险点,每一条都是”做不到就拒绝生成”级别的硬约束。
复制以下内容到 .kiro/steering/security-guardrails.md:
# Security Guardrails
## Input Validation
- Every API endpoint parameter MUST be validated with Zod schema before use
- All user-supplied strings MUST be sanitized before storage (strip HTML tags, trim)
- File upload endpoints MUST validate MIME type server-side, not from client headers
## Database
- All SQL queries MUST use parameterized queries. Never concatenate user input into SQL strings.
- Every SELECT/UPDATE/DELETE on tenant-owned data MUST include `WHERE tenant_id = $currentTenant`
- Database credentials MUST be read from environment variables, never hardcoded
## Authentication & Authorization
- Every API route MUST verify JWT/session before accessing request body
- Admin-only routes MUST use a separate middleware from regular auth
- Rate limiting MUST be applied to /api/auth/* routes (max 5 attempts per IP per minute)安全文件跟代码风格文件有一个本质区别:安全文件应该用 always inclusion mode,风格文件用 auto。
为什么?因为安全约束需要在每次代码生成时生效,不管 Kiro 判断当前任务是否涉及安全问题。AI 在生成一个”看起来跟安全无关”的 CRUD 接口时,也可能写出不带参数校验的 handler。这正是安全漏洞的来源。Kiro 的 auto 模式会根据任务上下文判断是否加载文件,对于安全规范,这个判断不够可靠。
每条规则的设计理由:
输入校验写了三条,不是一条,因为 AI 最容易漏的不是”要做校验”,是校验的覆盖面。“所有 API 端点参数必须 Zod 校验”是一个硬触发规则,但 AI 可能绕过去的方式是:校验了 body,忘了 query params;校验了 string,忘了 file upload。三条一起写才能堵住。
多租户隔离的 WHERE tenant_id 不能写成”建议加上”,必须写 MUST include。AI 对”建议”的理解是”可以先生成再提醒”,对 MUST 的理解是”不加这句不要生成”。在多租户数据泄漏这个风险等级上,你要的是后者。
认证中间件的规则写了两条(JWT 校验 + Admin 独立中间件),因为 AI 在”快速生成一个 admin 接口”时最自然的做法是复制普通接口的中间件然后改一下。你不告诉它 admin 需要独立中间件,它不会自己加。
Brian 的建议:安全文件写完之后,用一句”脏话测试”来验证。随便找一段你写的安全约束,把它改成相反的表述(比如把”Must use parameterized queries”改成”允许拼接 SQL 字符串”),然后让 Kiro 生成一个查询函数。如果 Kiro 生成了拼接 SQL,说明这条约束真实生效了。如果没生成,说明约束措辞不够强。
四、模板三:performance-policy.md 怎么阻止 AI 的 N+1 查询?
Answer Capsule: AI 生成数据库查询时最常见的性能问题就是 N+1 查询:一条查询外层列表,循环内每条记录再单独查一次。性能策略文件用 10 行规则强制 AI 在生成任何数据访问代码时先过”分页+索引+批量加载”三道关卡。
复制以下内容到 .kiro/steering/performance-policy.md:
# Performance Policy
## Database Queries
- All list queries MUST have pagination (LIMIT + OFFSET or cursor-based)
- Every query MUST use an indexed column in WHERE clause. If no index exists, add a comment `-- TODO: add index`
- N+1 queries are forbidden. Use eager loading (`.include()`) or batch queries (`.findMany([...ids])`)
- Never execute SQL inside a loop body
## API Responses
- List endpoints MUST return `{ data: [], total: number, cursor?: string }` shape
- Response payload over 1MB MUST use pagination or streaming
## Frontend
- Images MUST use `loading="lazy"` attribute
- Bundle size per route MUST stay under 200KB (verify with `npm run build -- --analyze`)性能文件的三条数据库规则对应三个 AI 高频失误场景:
忘了分页。 AI 在生成长列表查询时,默认行为是”查出来全部返回”。如果表里有 10 万行,一次查询把数据库和 API 的带宽全打满。这条规则强制每次列表查询都带 LIMIT。
走了全表扫描。 AI 不关心索引。它会在 WHERE 里写 WHERE status = 'active',而 status 列上可能没有索引。让你注意到索引缺失的是线上慢查询日志,不是 AI。这条规则强制 AI 检查 WHERE 列。
N+1 查询。 这是 AI 生成 ORM 代码的头号性能杀手。比如:查 100 个用户 → 循环每个用户查各自订单。AI 按”逻辑自然顺序”写代码:先查用户,再查订单。它不会自动优化成 eager loading。必须写进规范里。
Brian 的建议:性能文件从这 10 行开始。不要一上来就写”Redis 缓存策略""CDN 配置”。这些属于架构设计,不是 Steering Files 该管的事。Steering Files 管的是”AI 每次都能自动做对”的基线性能规则。
五、Steering Files 怎么维护才不”过期”?一套轻量治理流程
Answer Capsule: 指定一个开发者做 owner,每周 1-2 小时维护窗口。四个 inclusion mode 按风险等级分配:安全类用 always,风格类用 auto,框架类用 fileMatch,实验性规则用 manual。每个文件底部加一行版本注释,3 个月后还能知道这条规则为什么存在。
5.1 指定 Owner,不要”团队共同负责”
“团队共同维护”翻译过来就是没人维护。指定一个人。这个人不是”写所有规则的人”,是”每周五下午花 1 小时过一遍变更需求的人”。职责包括:新增模块时在 Steering Files 里补对应的规范条目、框架升级后删掉过时规则、Code Review 中发现重复提出的问题提炼成新的约束。
成都那个 8 人团队的案例已经证明了:没人维护的 Steering Files 约 3 个月后变成负资产。
5.2 Inclusion Mode 选择指南
Kiro 提供四种 inclusion mode,按风险等级分配:
| Mode | 什么时候用 | 适用文件 | 关键考量 |
|---|---|---|---|
always | 每次代码生成都必须加载 | security-guardrails.md | 安全约束不能靠 AI 判断”这次用不用” |
auto | Kiro 根据任务上下文自动判断 | coding-standards.md, performance-policy.md | 省 token,但对于非歧义规则足够可靠 |
fileMatch | 按文件类型匹配加载 | 框架特定规范(如 Next.js 路由约定) | 只在匹配文件触发,token 最省 |
manual | 开发者手动指定 | 实验性规则、临时补丁规则 | 在推广到 auto 之前先试用一周 |
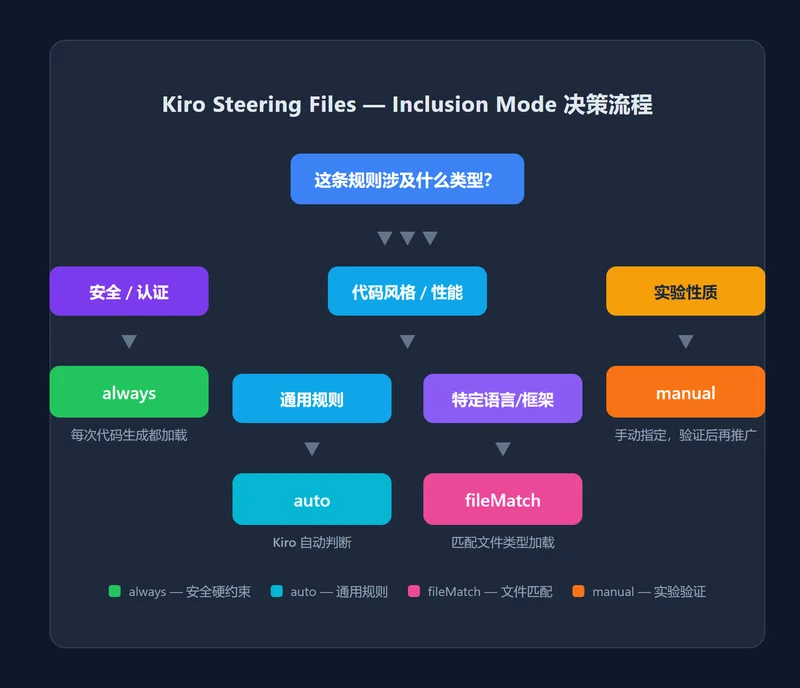
一个常被问的问题:为什么不把所有文件都设成 always?因为 token 预算。Kiro 的 Agent 每次生成代码时,上下文窗口里同时装着 spec 文档 + 业务代码 + Steering Files。Steering Files 占的 token 越多,留给业务逻辑理解的 token 越少。前文上海金融团队的 6 文件 38 页翻车案例就是这个问题。
5.3 版本注释:3 个月后还能知道这条规则为什么存在
每个 Steering File 底部加一行:
<!-- version: 2026-05-25-v1, owner: @zhang-san, reason: initial setup from Kiro template -->这条注释对 Kiro 不可见(HTML 注释),但对维护者有用。3 个月后有人问”为什么要限制 bundle size 200KB”,翻这条注释能追溯到原始决策。
Brian 的建议:治理流程不要设计太重。Owner 每周 1-2 小时,版本注释一行,inclusion mode 从 auto 开始(安全文件除外)。如果你花在管理 Steering Files 上的时间超过了写代码时间的 5%,说明你写了太多规则或者规则写太细了。回第二、三、四节检查:每条规则是否仍然是”AI 可直接执行的指令”。
六、常见问题 FAQ
Q: Steering Files 应该放在哪个目录?
放在项目根目录的 .kiro/steering/ 下。Kiro 初始化时运行 kiro init 会自动创建该目录。Steering Files 是 Markdown 格式,Kiro 在每次代码生成时加载这些规则作为硬约束,不是可选建议。
Q: Steering Files 一个文件写多长合适?
单个文件控制在 10-20 行。超过 20 行,Kiro 的上下文窗口被规范占满,留给业务逻辑的空间不够。三个核心文件(代码风格/安全/性能)各 10-20 行,总计不超过 60 行。以后每新增一个文件,审视是否可合并到现有文件中。
Q: 四种 inclusion mode(always/auto/fileMatch/manual)怎么选?
安全类用 always(每次生成都加载),风格和性能类用 auto(Kiro 根据任务上下文自动判断),框架特定规范用 fileMatch(匹配文件类型时加载),实验性规则用 manual(手动指定)。安全文件不建议用 auto,因为 Kiro 可能判断当前任务”不涉及安全问题”而跳过一个本该生效的约束。
Q: Steering Files 需要定期更新吗?
需要。建议指定一个开发者每周投入 1-2 小时维护:新增模块时添加对应的规范条目,过时规则及时删除。如果不维护,约 3 个月后 Steering Files 与实际代码库的差距会拉大到 AI 开始”忽略”过时规则的程度。
Q: 小团队(3 人以下)也需要 Steering Files 吗?
3 人以下团队如果成员编码风格本就一致,Steering Files 的边际收益有限。但安全规范文件(security-guardrails.md)即使单人开发也建议配置,AI 生成代码的安全漏洞不随团队规模变化。一句话:安全文件人人需要,风格文件看团队规模。
Q: 怎么验证 Steering Files 真的在生效?
用”反向测试”:把某条规则改成相反的表述(比如把”禁止 throw”改成”允许 throw”),然后让 Kiro 生成相关代码。如果生成的代码跟着变了,说明这条规则被 Kiro 读取并执行了。如果没变,说明规则措辞太弱或 inclusion mode 配置有问题。
Q: Steering Files 和 Kiro Specs(requirements/design/tasks)有什么区别?
Spec 文件是一次性的——一个需求写一份 spec,任务完成就归档。Steering Files 是永久性的:它描述的是团队的技术基线,每次代码生成都会参考。类比:Spec 是”这个需求怎么做”,Steering Files 是”我们团队怎么写代码”。
总结:3 套模板速查
| 文件 | 行数 | Inclusion Mode | 核心约束 | 维护频率 |
|---|---|---|---|---|
| coding-standards.md | 14 | auto | 命名/文件结构/错误处理三统一 | 6 个月审一次 |
| security-guardrails.md | 20 | always | 输入校验/SQL 防护/多租户隔离 | 每次新增 API 模块时检查 |
| performance-policy.md | 10 | auto | 分页/索引/N+1 禁止 | 3 个月审一次 |
起步路径:今天复制这 3 个文件到 .kiro/steering/,安全文件设成 always,其余设成 auto。指定一个 owner,下周五花 1 小时过第一轮变更。3 周后根据实际效果决定是否加第 4、第 5 个文件。
关于 SevenColorYun
作为 AWS APN Premier 级合作伙伴,我们已为 20+ 开发团队提供 Kiro 开发环境配置与 Steering Files 落地咨询服务。
我们的服务:
- Kiro Spec-Driven 开发流程落地咨询(Steering Files 规范模板 + 团队培训 + 治理流程设计)
- AWS Bedrock Claude API 独占带宽通道开通(On-Demand + Provisioned Throughput,避免 Kiro Agent 限速中断)
- 全产品线充值采购(充值返赠 5% 起,覆盖 Bedrock、EC2、RDS 等)
- 人民币对公付款 + 国内增值税专用发票
需要帮助?点击右下角联系我们的技术顾问,获取 Kiro 团队部署方案 与 Steering Files 专属配置模板,或了解 阿里云国际版充值赠金 降低云基础设施成本。


